As of April 9, 2026, Apple’s pretty clear about what Foundation Models are and aren’t.
The on-device model is 3 billion parameters, optimized for device-scale tasks like summarization, extraction, classification, and similar app-integrated work. It’s not designed for world knowledge or advanced reasoning. Developers are expected to break tasks into smaller pieces and use session APIs, guided generation, tool calling, and transcripts to build reliable apps around the model. Not to expect it to do everything.
Apple also documents a hard 4,096-token context window. Exceed it and you get LanguageModelSession.GenerationError.exceededContextWindowSize(_).
That framing matters. What we built is interesting precisely because it works inside those limits, not by pretending they don’t exist.
The starting constraint
Most people look at a 3B on-device model with a 4K context window and think the ceiling’s obvious. Lightweight chat, short summaries, simple extraction, maybe a tool call or two. Then it should start to break.
Fair enough.
A model that small isn’t supposed to behave like a deep research engine. It’s not supposed to repeatedly search the web, keep the right evidence alive over many turns, and return a long grounded report without either overflowing its context or drifting into filler.
That’s exactly why I wanted to test it.
The question wasn’t whether Foundation Models could call a tool. Too easy a benchmark. I wanted to know if a small on-device model could become a serious research agent when the surrounding system was designed right.
What Apple actually gives you
Apple gives developers a strong local runtime, but not a complete research system.
| What you get | What you don’t get |
|---|---|
| On-device 3B model | Strong world knowledge |
| Generation APIs | Long-horizon reasoning |
| Session and transcript support | Built-in research planning |
| Guided generation | Robust context management for tool-heavy loops |
| Tool calling | Automatic evidence retention under pressure |
| Privacy-preserving local inference |
So the mental model isn’t “the model is the product.” It’s:
small model + strong runtime architecture = usable research systemThat’s the gap we were trying to close with Swarm.
The architecture

The final stack:
| Component | Role |
|---|---|
| Foundation Models | Generation, rewriting, section synthesis, final report-writing passes |
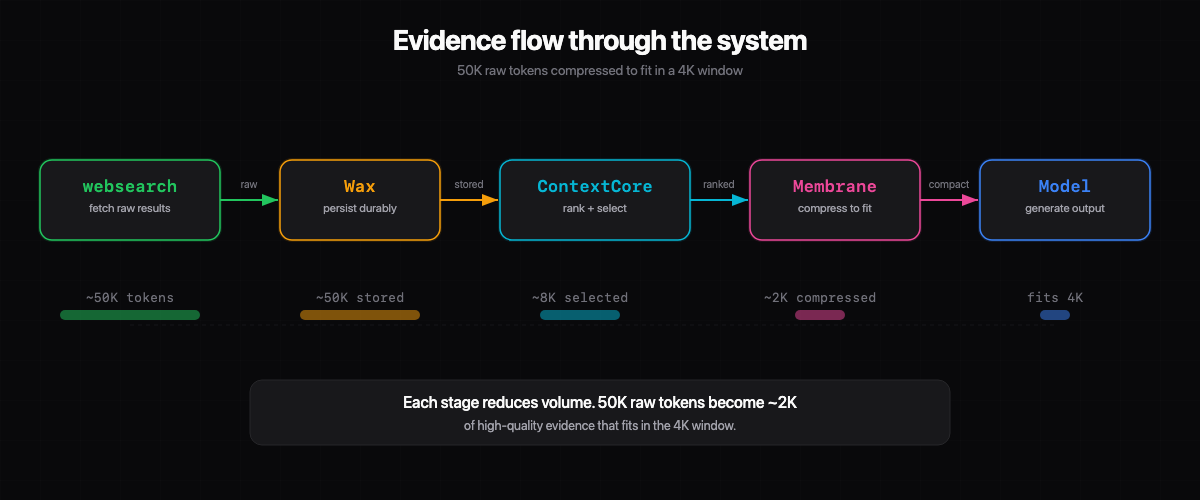
| websearch | World knowledge. Real live tool, not a mock or replay fixture |
| Wax | Durable evidence storage. Persists what the model might need later, makes it recallable |
| ContextCore | Decides which context is worth bringing back. Ranking, packing, compression |
| Membrane | Keeps the prompt alive under budget pressure. Pointerizes or reduces large tool outputs |
| Swarm | Orchestrates the whole loop: tool use, evidence handling, memory flow, section writing |
The core idea: the model was never asked to be everything.
The real problem
The naive version failed in exactly the ways you’d expect a small tool-using model to fail. Malformed or weak tool calls. Generic refusals after a tool succeeded. Repeated or low-value searches. Context overflow after a few real search results. Summaries that ignored the actual retrieved evidence.
One thing became obvious fast. This wasn’t a prompt problem. It was a systems problem.
If a 4K model is carrying raw search outputs, repeated tool calls, and broad conversation history all in one live loop, it’s going to fail no matter how clever the instructions look.
The real questions: how do we make repeated tool calls survive the context budget? How do we retain evidence without replaying everything? How do we make the final writing stage grounded instead of speculative?

Where the stack became necessary
Membrane solved survival
Without Membrane, repeated tool use burns through the live prompt way too fast.
Every tool schema, every search hit, every snippet, every retrieved artifact competes for the same limited window. In our strict4k setup, the model can’t afford to keep large tool outputs inline.
Membrane trims what the model needs to see in the active loop. That makes repeated tool calls viable where they otherwise wouldn’t be.
I don’t think of Membrane as a nice optimization. It’s core infrastructure for small-model agent loops.
ContextCore solved selection
Surviving the context window isn’t enough. You can keep a run alive and still produce garbage if the wrong evidence survives.
ContextCore packs recent turns, recalled evidence, and active working context into a bounded window instead of blindly replaying history. It decides what matters. Overflow stops being a fatal event and becomes a selection event.
Wax solved durability
The system needs a place to keep the truth without forcing it to live inside every prompt. Wax gave us that durable layer.
This mattered even more once the workflows got longer. The live prompt could stay compact while the system still had access to the underlying search evidence.
The biggest design shift
The most important change we made: we stopped trusting the model to do unconstrained research planning.
Sounds harsh, but it’s the right call for a small on-device model.
If you ask the model to “research Cristiano Ronaldo,” it’ll often issue broad, repetitive, or generic searches. Even when it doesn’t fail outright, the search quality is inconsistent.
So instead of asking the model to invent the research plan, we moved to deterministic retrieval. For the Ronaldo report, the workflow was split into five topic areas: early life and Sporting CP, club career, Portugal and international legacy, playing style and records, commercial and cultural impact.
Each topic got explicit search queries and domain preferences.
Retrieval became predictable and auditable. The model was still doing real work, but it wasn’t responsible for inventing the whole evidence-gathering strategy under pressure. Respecting the model’s limits instead of fighting them.
The first non-obvious bug
One of the more interesting failures had nothing to do with the model.
At one point, the Ronaldo research paper started pulling in unrelated content from prior work. The report was supposed to be about football, but it began referencing completely unrelated technical material from earlier runs. I stared at that for a while before realizing what happened.
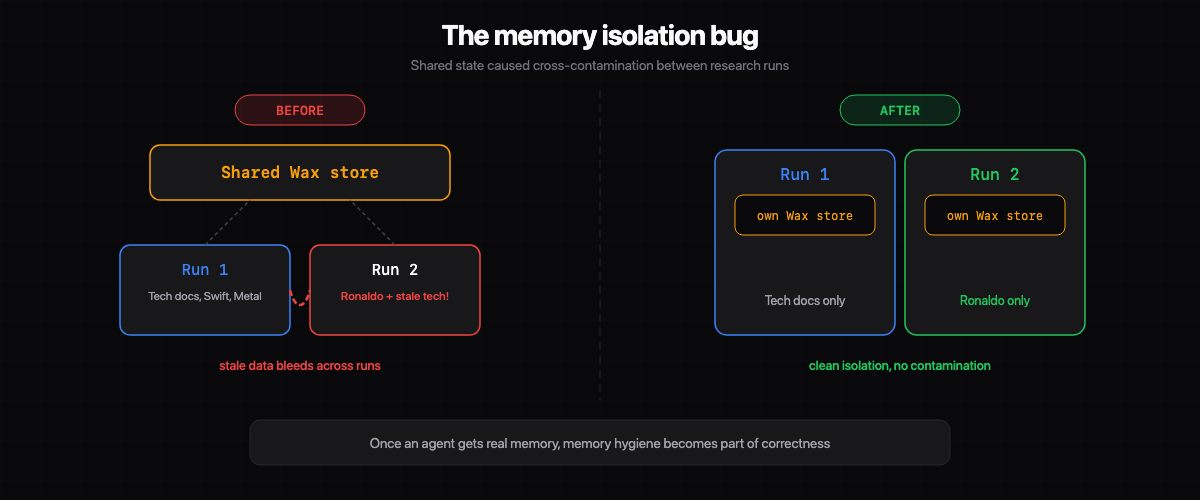
Not a generation issue. A memory isolation issue.
We were reusing shared evidence and memory in ways that let stale material bleed into a new run. The fix was isolating the workflow onto fresh Wax and web-evidence stores per run.
That bug taught me something I keep thinking about: once an agent gets real memory, memory hygiene becomes part of correctness. If you don’t isolate runs properly, the system can be coherent while still being wrong. That’s a weird failure mode.
The writing pipeline
Even after the retrieval side improved, the writing side still needed discipline.
A small model likes to smooth gaps. If the evidence is incomplete, it’ll fill in the missing structure with plausible but weak prose. I’ve watched it do this enough times to recognize the pattern immediately.
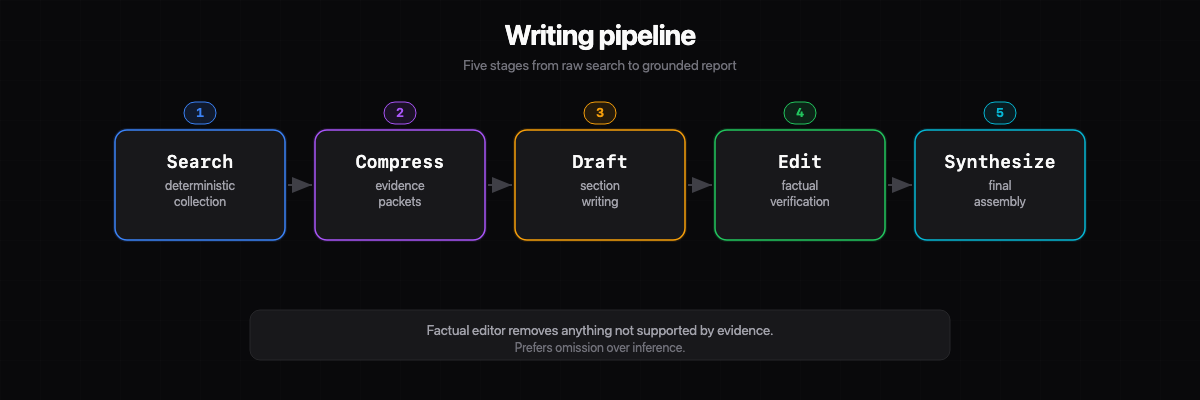
So the workflow became multi-stage:
| Stage | Purpose |
|---|---|
| 1. Deterministic search collection | Predictable, auditable retrieval per topic |
| 2. Compact evidence packet generation | Distill raw search results into usable packets |
| 3. Section drafting | Model writes from curated evidence |
| 4. Factual editing pass | Remove anything not supported by evidence. Prefer omission over inference |
| 5. Final synthesis | Assemble sections into coherent report |
That change helped a lot. The output got less flashy and more trustworthy. Exactly the tradeoff you want in a research system.
The live result
The final live verified Ronaldo run:
| Metric | Value |
|---|---|
| Websearch calls | 20 (real, live) |
| Topic sections | 5 |
| Word count | 2,336 |
| Context profile | strict 4K |
| Generation model | Apple Foundation Models (3B, on-device) |
| Retrieval | websearch (live) |
I keep coming back to that number. Not because 2,336 words is huge, but because a 3B on-device model under a tight context budget produced it while remaining grounded in live retrieval. That still feels a little surreal to me.
Sources in the final paper included Britannica, UEFA, Guinness World Records, Forbes, Instagram, Look to the Stars, and FIFA publications.
The model didn’t know all of this. The system knew how to fetch, retain, and re-present the right evidence so the model could do useful work with it. That’s a very different thing.
Why this matters
The easy reaction: “Sure, but it still needed architecture.”
Yes. That is the point.
People talk about small models as if usefulness is determined only by parameter count. In practice, the runtime architecture matters just as much. Maybe more.
| Small model weaknesses | Small model strengths (with architecture) |
|---|---|
| Unconstrained planning | Writing from curated evidence |
| Noisy source selection | Editing for factual discipline |
| Remembering long raw transcripts | Synthesizing across bounded inputs |
| Recovering from retrieval drift | Following a structured workflow |
We didn’t try to turn a 3B model into a frontier model. We tried to make it useful. Much better engineering target.
How the pieces fit
If I had to reduce the whole design to one sentence:
Wax remembers, ContextCore chooses, Membrane makes it fit, Swarm forces the model to stay inside that discipline.
What I like most about this architecture is that it isn’t about adding layers for the sake of it. It’s about separating responsibilities cleanly enough that the model only gets asked to do work it can actually do well. Feels like engineering, not wishful prompting.
The honest caveat
I’m not going to oversell this.
Foundation Models didn’t suddenly become a perfect deep research engine. There’s still work to do around source ranking, evidence normalization, contradiction checks between sections, citation auditing, and stronger section-specific verification.
I wouldn’t publish a piece like this without one more editorial pass if the stakes were high.
But that doesn’t diminish what happened. A small on-device model went much further than most people would expect when the surrounding system was designed well.
Why I care about this
Context limits are often treated like hard ceilings when they’re really systems constraints.
If retrieval is sloppy, memory is polluted, and prompt construction is naive, even a larger model will waste its window. If retrieval is disciplined, memory is clean, and the live prompt only contains what matters, even a small model can do work that initially looks out of reach.
The limit was never just the 4K window. It was how intelligently the system used it.
What comes next
The next step isn’t more tool calls. We already proved the system can survive a long live research loop.
It’s better quality. Better ranking, better evidence extraction, contradiction-aware editing, stronger citation validation, more topic-specialized research workflows. That’s how this stops being a demo and starts being a real local research system.
The result already changed my priors. A 3B on-device model with a 4K context window is much more capable than it looks if you build the right environment around it.